Регулярні мови, кінцеві автомати й лексичний аналіз

Матриця переходів КА будується в такий спосіб: стовпці матриці відповідають символам із вхідного алфавіту, рядка — символам з алфавіту станів, а елементи матриці відповідають станам, у які переходить КА для даної комбінації вхідного символу й символу стану. Якщо КА виявляється в ситуації (,), що не є лівою частиною якої-небудь команди, то він зупиняється. Якщо ж УУ вважає всі символи ланцюжка а… Читати ще >
Регулярні мови, кінцеві автомати й лексичний аналіз (реферат, курсова, диплом, контрольна)
Розробка лексичного аналізатора виконується досить просто, якщо при цьому скористатися добре розробленим математичним апаратом — теорією регулярних мов і кінцевих автоматів. У рамках цієї теорії класи однотипних лексем (ідентифікатори, константи й т.д.) розглядаються як формальні мови (мова ідентифікаторів, мова констант і т.д.), безліч пропозицій яких описується за допомогою відповідної граматики, що породжує. При цьому мови ці настільки прості, що вони породжуються найпростішої із граматик — регулярною граматикою (граматика класу 3 в ієрархії Хомского). Побудована регулярна граматика є джерелом, по якому надалі конструюється обчислювальний пристрій, що реалізує функцію розпізнавання пропозицій мови, породжуваного даною граматикою. Для регулярних мов таким пристроєм є кінцевий автомат. Нижче будуть розглянуті основні поняття теорії регулярних мов і кінцевих автоматів і її практичне використання при розробці алгоритмів ідентифікації лексем.
2.2.1 Граматика, Що Породжує, G =, правила який мають вигляд: А — > ав або З — > b, де А, В, З N; a, b T називається регулярної (автоматної).
Мова L (G), породжуваний автоматною граматикою, називається автоматним (регулярним) мовою або мовою з кінцевим числом станів.
Математичною моделлю процесу розпізнавання регулярної мови є обчислювальний пристрій, що називається кінцевим автоматом (КА). Термін «кінцевий» підкреслює те, що обчислювальний пристрій має фіксований і кінцевий обсяг пам’яті й обробляє послідовність вхідних символів, що належать деякій кінцевій безлічі. Існують різні типи КА, якщо функцією виходу КА (результатом роботи) є лише вказівка на те, припустима чи ні вхідна послідовність символів, такий КА називають кінцевим розпізнавателем. Саме цей тип КА надалі ми й будемо розглядати.
2.2.2 Визначення Кінцевим автоматом називається наступна п’ятірка: А =, де V = {а1 а2,., am — вхідний алфавіт (кінцева безліч символів);
— алфавіт станів (кінцева безліч символів);
— функція переходів;
— початковий стан кінцевого автомата;
— безліч заключних станів.
На змістовному рівні функціонування КА можна представити в такий спосіб.
Схематично конструкція КА показана на рис. 2.2.
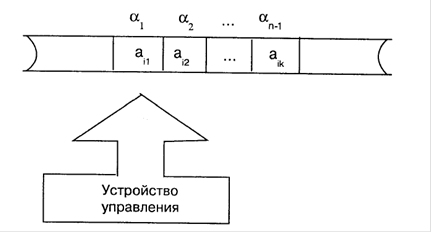
Рис. 2.2 Схема кінцевого автомата
Відображення (функцію переходів КА) можна представити різними способами. Основні з них:
сукупність команд;
діаграма станів;
матриця переходів.
Команда кінцевого автомата записується в такий спосіб:
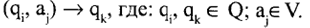
Дана команда позначає, що КА перебуває в стані, читає зі стрічки символ, а й переходить у стан .
Графічно команда представляється у вигляді дуги графа, що йде з вершини у вершину й позначеної символом вхідного алфавіту:
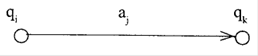
Графічне подання всього відображення називають діаграмою станів кінцевого автомата. Діаграма станів у цьому випадку — це орієнтований граф, вершинам якого поставлені у відповідність символи з безлічі станів Q, а дугам — команди відображення .
Якщо КА виявляється в ситуації (,), що не є лівою частиною якої-небудь команди, то він зупиняється. Якщо ж УУ вважає всі символи ланцюжка а, записаної на стрічці, і при цьому перейде в заключний стан, то говорять, що ланцюжок допускається кінцевим автоматом.
Матриця переходів КА будується в такий спосіб: стовпці матриці відповідають символам із вхідного алфавіту, рядка — символам з алфавіту станів, а елементи матриці відповідають станам, у які переходить КА для даної комбінації вхідного символу й символу стану.
Як було зазначено раніше, КА є гарною математичною моделлю для подання алгоритмів розпізнавання лексем у ЛА, особливо для лексем з нескінченних класів. При цьому джерелом, по якому будується КА, є регулярна граматика.
Нехай задана регулярна граматика G =, правила який мають вигляд: або, де й .
Тоді кінцевий автомат, А = 0, F>, що допускає та ж сама мова, що породжує регулярна граматика G, будується в такий спосіб [7]:
- 1) V = T;
- 2) Z — заключний стан КА;
- 3) q0 = {S};
- 4) F = {Z};
- 5) Відображення будується у вигляді:
кожному правилу підстановки в граматиці G виду ставиться у відповідність команда ;
кожному правилу підстановки виду ставиться у відповідність команда ;
Розрізняють детерміновані й недетерміновані кінцеві автомати. КА називається недетермінованим КА (НДКА), якщо в діаграмі його станів з однієї вершини виходить кілька дуг з однаковими позначками.
У загальному випадку може бути запропонований наступний порядок конструювання лексичного аналізатора:
Крок 1. Виділити у вхідній мові L (G) на підставі опису його синтаксису за допомогою Кс-Граматики G безліч класів лексем Li, l.
Крок 2. Побудувати для кожного класу лексем Li автоматну граматику Gi, що породжує мова Li, тобто Li = L (Gi).
Крок 3. Для кожної автоматної граматики Gi побудувати діаграму станів Di — неформальну модель распознавателя мови L (Gi).
Крок 4. Визначити умови виходу з ЛА (перехід ЛА в початковий стан) при досягненні кінця довільної лексеми з кожного класу лексем L (Gi).
Крок 5. Розбити символи вхідного алфавіту на непересічні класи.
Крок 6. Побудувати матрицю переходів лексичного аналізатора.
Крок 7. Вибрати формат і код образів лексем-дескрипторів виду (, адреса в таблиці>).
Крок 8. Запрограмувати семантичні підпрограми і розпізнати за склеєною діаграмою переходів.